

RTX40 系列游戏本与台式机显卡 AI 计算力对比
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
RTX40 系列游戏本还有几天就上市了商家选了个比较特别的日子2 月 22 号 22:00真是有心了。为了用游戏本做 AI 的朋友选的时候有的放矢特意查了一下 RTX40 系列的 CUDA 核心与频率计算一下 FP32 TFLOPS便于比较。
笔记本 GPU
RTX40 系列笔记本 GPU

RTX30 系列笔记本 GPU
RTX30 系列的游戏本还占有较大的市场估计随着 RTX40 系列游戏本的推出价格上可能会有一些优惠性价比会有提高也可以关注一下。

RTX40 系列与 RTX30 系列游戏本对比
NVIDIA 给出的测试显示RTX40 系列笔记本 GPU 性能比上一代有较大的提高

除了加速频率的提升还得益于构架的升级

RTX40 系列与RTX30 系列游戏本计算力对比
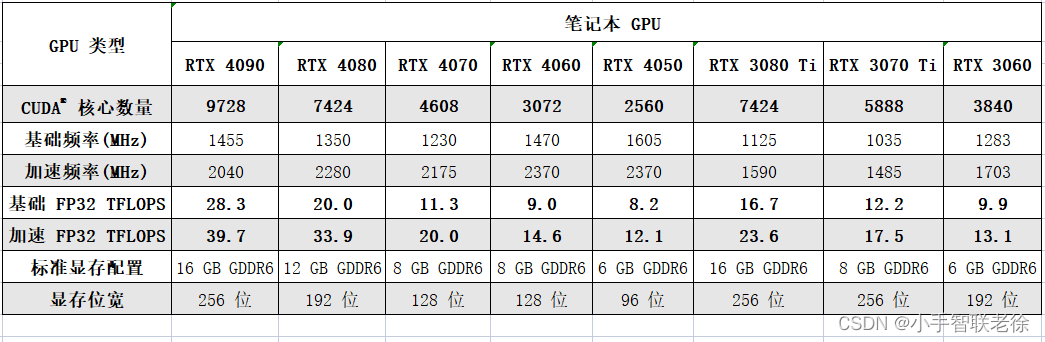
台式机显卡
RTX40 系列台式机 GPU
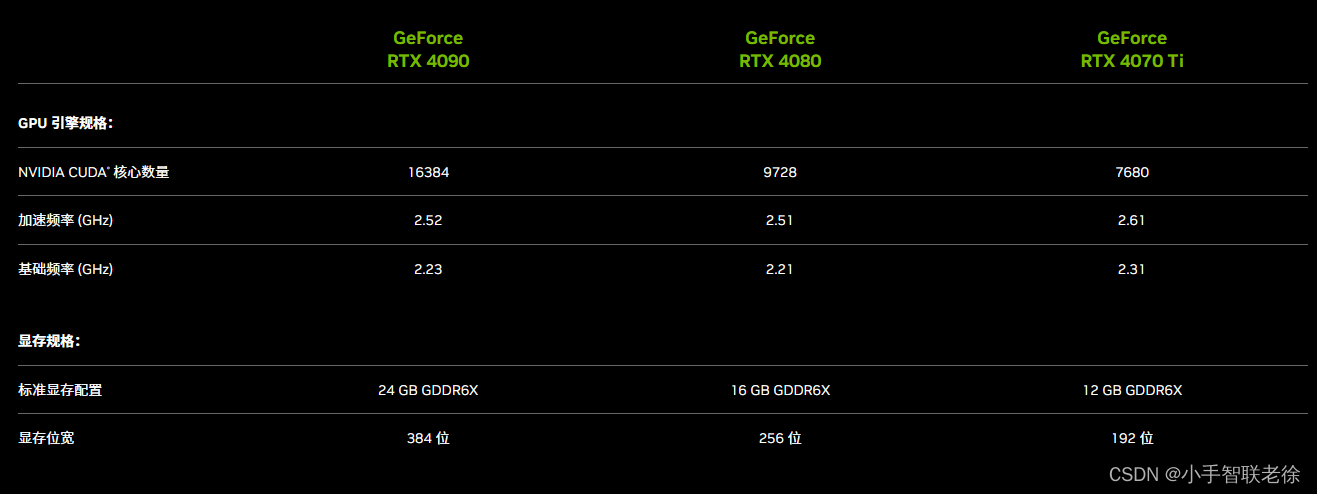
RTX30 系列台式机 GPU

RTX40 系列与 RTX30 系列台式机显卡对比
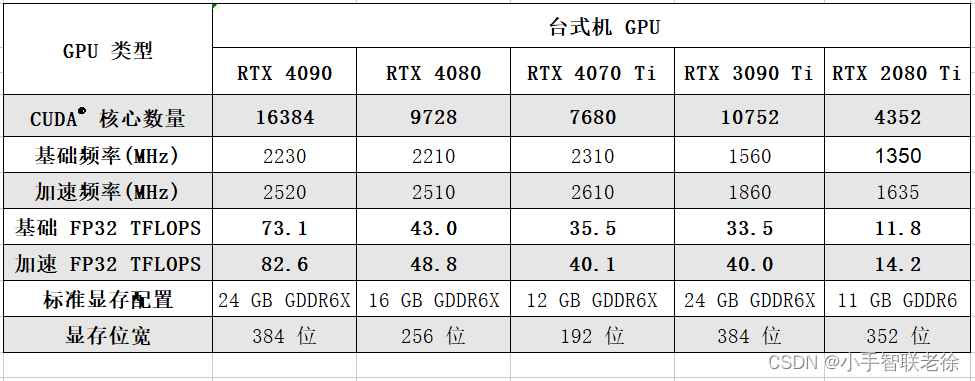
小结
比较 RTX30 与 RTX40 系列的游戏本 GPU不难发现稍低端的 RTX4060 与 RTX3060 的 TFLOPS 差别不大而且 RTX4060 的位宽比 RTX3060 低估计老黄的刀法是冲着 10~20 TFLOPS 去的差不多够用就得了再高了散热和性价比就不好控制了高端的 RTX4090 游戏本的 FP32 达到了接近 40 TFLOPS目前来看不能再高了再高估计散热就 Hold 不住了。
RTX4090 台式机显卡的 FP32 达到了 82.6 TFLOPSRTX4070Ti 也到了 40.1 TFLOPS超过了上一代的旗舰 RTX3090Ti性能再低的就看看游戏本得了。
目前比较火的 ChatGPT底层拥有一个 1750 亿参数的预训练大模型支撑其算力基础设施至少需要上万颗英伟达 GPU A100( 19.5 TFLOPS)一次模型训练成本超过 1200 万美元训练阶段总算力消耗约为 3640PF-days即1 PetaFLOP/s效率跑3640天如果采用 121 块最新的 RTX4090 台式机显卡不停的跑得跑一整年
老徐2023/2/17