

【机器学习合集】参数初始化合集 ->(个人学习记录笔记)-CSDN博客
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
文章目录
综述
这些是不同的权重初始化方法用于初始化神经网络的权重参数。它们的主要区别在于初始化权重的策略和数学原理。以下是这些初始化方法的简要介绍和区别
简单初始化Zero Initialization
- 策略所有权重初始化为零。
- 区别这是最简单的初始化方法但通常不建议使用因为在多层神经网络中所有的神经元将拥有相同的权重导致对称性问题不利于学习。
随机初始化Random Initialization
- 策略权重以随机小的值初始化通常在[-ε, ε]的范围内其中ε是一个很小的正数。
- 区别随机初始化打破了对称性允许神经网络从不同的起点开始学习改善了训练过程。
固定方差初始化Fixed Variance Initialization
- 策略权重初始化时使用一个固定的方差通常是从正态分布中选择的。
- 区别这个方法确保权重的分布具有相对一致的方差但不一定适用于所有网络结构和任务。
方差缩放初始化Variance Scaling Initialization
- 策略权重初始化时方差根据网络的输入和输出的维度进行缩放通常以特定的方式选择。
- 区别这个方法试图通过权重初始化来平衡信号的方差以防止梯度消失或爆炸问题并有助于更稳定的训练。
He初始化He Initialization
- 策略权重初始化是根据网络的输入和输出的维度进行的方差被设置为2/n其中n是权重连接的输入维度。
- 区别He初始化是为深度卷积神经网络设计的通过设置适当的方差可以提高网络的学习速度和性能。
正交初始化Orthogonal Initialization
- 策略权重初始化是通过生成正交矩阵来实现的确保权重之间彼此正交。
- 区别正交初始化有助于减少权重之间的冗余信息提高网络的效率和学习性能。
MSRA初始化Microsoft Research for Advanced Initiative Initialization
- 策略权重初始化是根据网络的输入和输出的维度进行的方差被设置为2/(n_in + n_out)其中n_in是输入维度n_out是输出维度。
- 区别MSRA初始化旨在平衡信号的方差以提高网络的训练速度和性能。
- 不同的初始化方法适用于不同的网络结构和任务。通常随机初始化、He初始化和MSRA初始化在深度神经网络中表现良好因为它们可以打破对称性有助于更快的收敛和更好的性能。选择正确的初始化方法通常是深度学习中的一个重要超参数需要根据具体的情况进行调整。

1. 全零与随机初始化

2. 标准初始化(固定方差)

3. Xavier初始化(方差缩放)

4. He初始化

5. 正交初始化


6. MSRA初始化
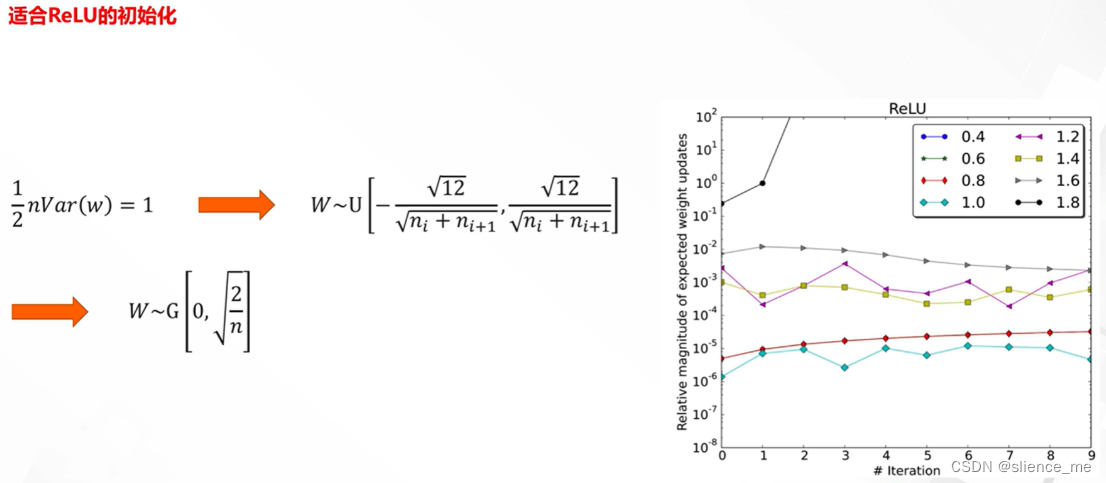
部分内容来自 阿里云天池、神经网络与深度学习(邱锡鹏著)
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |