

机器学习实战教程(⑤):使用PCA实战人脸降维
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |
1.引言
在互联网大数据场景下我们经常需要面对高维数据在对这些数据做分析和可视化的时候我们通常会面对「高维」这个障碍。在数据挖掘和建模的过程中高维数据也同样带来大的计算量占据更多的资源而且许多变量之间可能存在相关性从而增加了分析与建模的复杂性。
我们希望找到一种方法在对数据完成降维「压缩」的同时尽量减少信息损失。由于各变量之间存在一定的相关关系因此可以考虑将关系紧密的变量变成尽可能少的新变量使这些新变量是两两不相关的那么就可以用较少的综合指标分别代表存在于各个变量中的各类信息。机器学习中的降维算法就是这样的一类算法。
主成分分析Principal Components Analysis简称PCA是最重要的数据降维方法之一。在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用。本篇我们来展开讲解一下这个算法。
2.相关概念
协方差矩阵
协方差(Covariance)目的是度量两个变量(只能为两个)线性相关的程度。
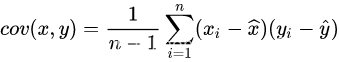
cov=0为可以说明两个变量线性无关但不能证明两个变量相互独立当cov>0时二者呈正相关cov<0时二者呈负相关。
- 协方差矩阵可以处理多维度问题。
- 协方差矩阵是一个对称的矩阵而且对角线是各个维度上的方差。
- 协方差矩阵计算的是不同维度之间的协方差而不是不同样本之间的。
- 样本矩阵中若每行是一个样本则每列为一个维度。
- 假设数据是3维的那么对应协方差矩阵为
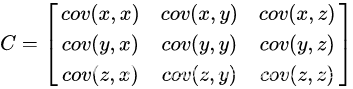
这里简要概括一下协方差矩阵是怎么求得的假设一个数据集有3维特征、每个特征有m个变量这个数据集对应的数据矩阵如下
 若假设他们的均值都为0可以得到下面等式
若假设他们的均值都为0可以得到下面等式
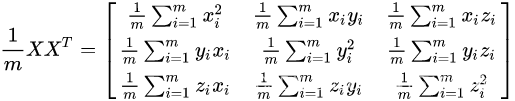
可以看到对角线上为每个特征方差其余位置为两个特征之间的协方差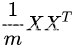
求得的就为协方差矩阵。
推导

如果列是特征公式为
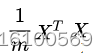
'''
假设列是矩阵特征代数里面是行表示特征
[
[x1,y2]
[x2y2]
]
求协方差是
[
[cov(x,x),cov(x,y)],
[cov(y,x),cov(y,y)],
]
'''
pc=np.array([[-1,4],
[-2,8],
[-7,2]
]);
mean_pa=np.mean(pc,axis=0)
print("均值",mean_pa)
pc_zero=pc-mean_pa
print(pc_zero)
print(pc_zero.T.dot(pc_zero)/(len(pc_zero)-1)) #注意样本的话是n-1啊全部数据集是n否则和np.cov对不上
print("conv",np.cov(pc,rowvar=False)) #rowvar=False表示列是特征默认行是特征
结果为
均值 [-3.33333333 4.66666667]
[[ 2.33333333 -0.66666667]
[ 1.33333333 3.33333333]
[-3.66666667 -2.66666667]]
[[10.33333333 6.33333333]
[ 6.33333333 9.33333333]]
conv [[10.33333333 6.33333333]
[ 6.33333333 9.33333333]]
协方差矩阵一定是方形矩阵第一矩阵列数n特征数决定了是n,n方形矩阵。
矩阵的行列式
行列式在数学中是一个函数其定义域为det的矩阵A取值为一个标量写作det(A)或|A|。无论是在线性代数、多项式理论还是在微积分学中比如说换元积分法中行列式作为基本的数学工具都有着重要的应用。
行列式等于零可以得出结论
- A的行向量线性相关
- A的列向量线性相关
- 方程组Ax=0有非零解
- A的秩小于n。n是A的阶数
- A不可逆
比如如果行列式=0说明x1y2-x2y1=0, x1=y1/y2 * x2 说明行线性相关。
[x1,x2
y1,y2]
[1,5
3,15] 该矩阵就是行列式=0例子。
矩阵的行列式是一个可以从方形矩阵方阵计算出来的特别的数。
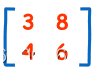
这矩阵的行列式是待会儿会解释计算方法
3×6 − 8×4 = 18 − 32 = −14
行列式告诉我们矩阵的一些特性这些特性对解线性方程组很有用也可以帮我们找逆矩阵并且在微积分及其他领域都很有用.
2×2 矩阵
2×2 矩阵 2行和2列
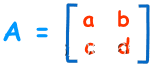
行列式是
|A| = ad - bc
“A 的行列式等于 a 乘 d 减 b 乘 c”
3×3 矩阵

行列式是
|A| = a(ei - fh) - b(di - fg) + c(dh - eg)
“A 的行列式等于。。。。。。”
乍看很复杂但这是有规律的
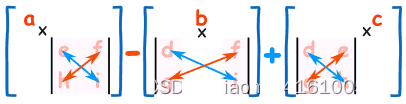
求 3×3 矩阵的行列式
- 把 a 乘以不在 a 的行或列上的 2×2 矩阵的行列式。
- 以 b 和 c 也做相同的计算
- 把结果加在一起不过 b 前面有个负号
公式是记着两边的垂直线 || 代表 “的行列式”
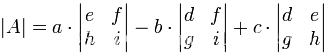
更多维计算参考
shuxuele
github
{kind=link}
numpy求行列式
#行列式一定是个方形矩阵
p_pet=np.array([[-1,4],
[-2,8]
]);
print(np.linalg.det(p_pet))
输出0
特征向量和特征值
得到了数据矩阵的协方差矩阵下面就应该求协方差矩阵的特征值和特征向量先了解一下这两个概念如果一个向量v是矩阵A的特征向量那么一定存在下列等式

其中A可视为数据矩阵对应的协方差矩阵是特征向量v的特征值。数据矩阵的主成分就是由其对应的协方差矩阵的特征向量按照对应的特征值由大到小排序得到的。最大的特征值对应的特征向量就为第一主成分第二大的特征值对应的特征向量就为第二主成分依次类推如果由n维映射至k维就截取至第k主成分。
求矩阵特征值的例子

如果入=4

numpy
#求特征值和特征向量
p_eig=np.array([[1.2,0.8],
[0.8,1.2]
]);
eigenvalue, featurevector =(np.linalg.eig(p_eig))
print(eigenvalue)
# 这里特征向量是进行单位化除以所有元素的平方和的开方的形式
# 比如入=0.4时特征向量是[-1,1],单位化[-1/开根(1**2+1**2)=-0.70710678 , -1/开根(1**2+1**2)=0.70710678]
# 比如入=2时特征向量是[1,1],单位化[1/开根(1**2+1**2)=0.70710678 , 1/开根(1**2+1**2)=0.70710678]
# 所以注意特征值2是第一列对应的是特征向量第一列的值作为向量
print(featurevector)
#组合特征值和特征向量
eig=[(eigenvalue[i],featurevector[:,i])for i in range(len(eigenvalue))]
print(eig)
输出
[2. 0.4]
[[ 0.70710678 -0.70710678]
[ 0.70710678 0.70710678]]
[(2.0, array([0.70710678, 0.70710678])), (0.3999999999999997, array([-0.70710678, 0.70710678]))]
可以理解为特征向量就是原始特征的一个基础向量最后生成一个和原始数据相同维度行是降维维度值的矩阵比如一个50行60列特征的矩阵需要降维到30个特征特征向量会是一个(30,60)的矩阵
3. 降维实现
通过上述部分总结一下PCA降维操作的步骤
- 去均值化
- 依据数据矩阵计算协方差矩阵
- 计算协方差矩阵的特征值和特征向量
- 将特征值从大到小排序
- 保留前k个特征值对应的特征向量
- 将原始数据的n维映射至k维中
公式手推
原始数据集矩阵每行代表一个特征:
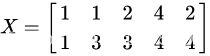
对每个特征去均值化

计算对应的协方差矩阵

依据协方差矩阵计算特征值和特征向量套入公式

拆开计算如下
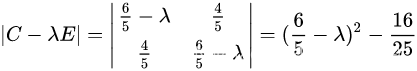
可以求得两特征值

当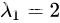
时对应向量应该满足如下等式
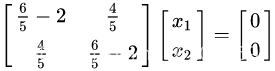
对应的特征向量可取为
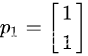
同理当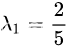
时对应特征向量可取为

这里我就不对两个特征向量进行标准化处理了直接合并两个特征向量可以得到矩阵P
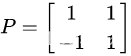
选取大的特征值对应的特征向量乘以原数据矩阵后可得到降维后的矩阵A
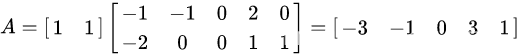
综上步骤就是通过PCA手推公式实现二维降为一维的操作。
手推转自https://juejin.cn/post/6844904177571758088
numpy实现降维
输出结果查看gitlab
#%%
import numpy as np;
import matplotlib.pyplot as plot;
# 数学中行是表示特征
X=np.array([
[1,1,2,4,2],
[1,3,3,4,4]
])
# 转置为列为特征
X=X.T
print(X)
#%%
#均值归零
x_demean=np.mean(X,axis=0)
X_Zero=X-x_demean
print("均值",x_demean)
print(X_Zero)
#%%
#计算对应的协方差矩阵,手撕或者使用np.conv
con=X_Zero.T.dot(X_Zero)/(len(X_Zero)-1)
con1=np.cov(X_Zero,rowvar=False)
print("协方差",con,"\n",con1)
#%%
#依据协方差矩阵计算特征值和特征向量,转换参考 矩阵计算.ipynb
f_value,f_vector=np.linalg.eig(con)
eig=[(f_value[i],f_vector[:,i])for i in range(len(f_value))]
print("特征值-特征向量",eig)
#%%
#获取最大值的索引
max_f_value_index=np.argsort(f_value)[::-1][0]
print(np.array([eig[max_f_value_index][1]]).dot(X_Zero.T))
print(X_Zero.dot(np.array([eig[max_f_value_index][1]]).T))
代码部分是公式的套用每一步后都有注释不再过多解释。可以看到得到的结果和上面手推公式得到的有些出入上文曾提过特征向量是可以随意缩放的这也是导致两个结果不同的原因eig方法计算的特征向量是归一化后的。
sklean实现降维
#%%
from sklearn.decomposition import PCA
import numpy as np
X = [[1, 1], [1, 3], [2, 3], [4, 4], [2, 4]]
X = np.array(X)
pca = PCA(n_components=1)
PCA_mat = pca.fit_transform(X)
print(PCA_mat)
这里只说一下参数n_components如果输入的是整数代表数据集需要映射的维数比如输入3代表最后要映射至3维如果输入的是小数则代表映射的维数为原数据维数的占比比如输入0.3如果原数据20维就将其映射至6维。
4. pca人脸数据降维
fetch_lfw_people人脸识别数据集是由n个人不同时间、不同角度、不同表情等图像组成的数据集
从我这统计目录结构有5760个人
这是小布什部分图(530个
下载并抓取图库
#读取人脸数据
from sklearn.decomposition import PCA
from sklearn.datasets import fetch_lfw_people
import matplotlib.pyplot as plt
faces=fetch_lfw_people(data_home="d:/test/face",min_faces_per_person=60)
print("图片数据维度",faces.images.shape) #数据维度1348张照片每张照片是一个62*47=2914的矩阵
print("图片二维数据维度",faces.data.shape)
X=faces.data #sklearn降维算法只接受二维特征矩阵把数据换成特征矩阵维度是1348*2914
X = faces.data
min_faces_per_person 提取的数据集将仅保留具有至少min_faces_per_person不同图片的人的图片
比如小布什的图片超过了60就加载出来比如Abdullah只有3张该用户就不会加载。
如果数据403无法下载请百度下载其他用户上传到类似百度盘数据解压到data_home指定的目录即可
输出
图片数据维度 (1348, 62, 47)
图片二维数据维度 (1348, 2914)
绘制原始图片绘制前32个
# 在matplotlib中整个图像为一个Figure对象。在Figure对象中可以包含一个或者多个Axes对象
# figsize代表画布的大小 3行8列表示子图axes大小
fig, axes = plt.subplots(3,8 #创建一个画布有3*8个子图
,figsize = (8,4) #创建一个大小为8*4的黄布
,subplot_kw = {"xticks":[],"yticks":[]} # 每个子图都不显示坐标轴
)
for i,ax in enumerate(axes.flat):
ax.imshow(faces.images[i,:,:], cmap = "gray")

pca降维到150维
pca=PCA(n_components=150)
V1 = pca.fit_transform(X)
x_inv = pca.inverse_transform(V1)
print("逆转升维维度",x_inv.shape)
V = pca.components_
print("降维后特征向量",V.shape)
print("降维后数据",V1.shape)
显示特征向量
fig, axes = plt.subplots(3,8 #创建一个画布有3*8个子图
,figsize = (8,4) #创建一个大小为8*4的黄布
,subplot_kw = {"xticks":[],"yticks":[]} # 每个子图都不显示坐标轴
)
for i,ax in enumerate(axes.flat):
ax.imshow(V[i,:].reshape(62,47), cmap = "gray")

显示降维数据
fig, axes = plt.subplots(3,8 #创建一个画布有3*8个子图
,figsize = (8,4) #创建一个大小为8*4的黄布
,subplot_kw = {"xticks":[],"yticks":[]} # 每个子图都不显示坐标轴
)
for i,ax in enumerate(axes.flat):
ax.imshow(x_inv[i].reshape(62, 47), cmap='binary_r')
