

机器学习实战——疫情数据分析与预测
| 阿里云国内75折 回扣 微信号:monov8 |
| 阿里云国际,腾讯云国际,低至75折。AWS 93折 免费开户实名账号 代冲值 优惠多多 微信号:monov8 飞机:@monov6 |

📢📢📢📣📣📣
🌻🌻🌻Hello大家好我叫是Dream呀一个有趣的Python博主多多关照😜😜😜
🏅🏅🏅Python领域优质创作者欢迎大家找我合作学习文末有名片欢迎+++
💕入门须知这片乐园从不缺乏天才努力才是你的最终入场券🚀🚀🚀
💓最后愿我们都能在看不到的地方闪闪发光一起加油进步🍺🍺🍺
🍉🍉🍉“一万次悲伤依然会有Dream我一直在最温暖的地方等你”唱的就是我哈哈哈~🌈🌈🌈
🌟🌟🌟✨✨✨
前言本文将带领大家爬取11个国家以及中国31个省自治区、直辖市在2022.0101-2022.06.19的新冠疫情数据。并且采用机器学习模型对2022.6.20-2022.6.30每一天的全国确诊人数、死亡人数、治愈人数进行预测做出疫情可视化图形并且求出最终的相关系数R2
本文目录
一、问题说明
1、爬取中国、美国、巴西、印度、俄罗斯、法国、英国、土耳其、阿根廷、哥伦比亚、日本等11个国家以及中国31个省自治区、直辖市在2022.0101-2022.06.19的新冠疫情数据。如果对数据爬虫技术不熟悉可使用data文件中提供的数据其中中国各省数据为confirmedCount、curedCount、deadCountworld_confirmedCount、world_curedCount、world_deadCount数据为11个国家的爬取数据。
2、根据爬取或提供的疫情数据将最近日期2022.06.19确诊病例数、死亡人数、康复人数在上述11个国家、国内各地区两个维度进行可视化展示如柱状图或者饼状图。
3、采用机器学习模型对2022.6.20-2022.6.30每一天的全国确诊人数、死亡人数、治愈人数进行预测。
4、2022.6.20-2022.6.30的确诊人数、死亡人数、治愈人数结果将在2022.7.1公布请根据真实结果计算决定系数R2最终以该系数作为本项目的最终得分
二、模型与算法
在模型算法方面这次我们选择的是LSTM算法LSTM是RNN的一个优秀的变种模型继承了大部分RNN模型的特性同时很利于解决本题大量数据的问题。
Long ShortTerm 网络是一种RNN特殊的类型可以学习长期依赖信息。LSTM和基线RNN并没有特别大的结构不同但是它们用了不同的函数来计算隐状态。LSTM的“记忆”叫做细胞可以直接把它们想做黑盒这个黑盒的输入为前状态h和当前输入x。这些“细胞”会决定哪些之前的信息和状态需要保留/记住而哪些要被抹去。实际的应用中发现这种方式可以有效地保存很长时间之前的关联信息。
在LSTM模型算法方面我们使用LSTM中的重复模块则包含四个交互的层三个Sigmoid
和一个tanh层以一种非常特殊的方式进行交互同时使用LSTM有通过精心设计的称作为“门”的结构来去除和增加信息到细胞状态。利用一个sigmoid神经网络层和一个pointwise乘法的非线性操作0代表“不许任何量通过”1就指“允许任意量通过”从而使得网络就能了解哪些数据是需要我们去遗忘哪些数据是需要我们去保存的得到我们真正需要去训练的数据即训练集这点在死亡人数数据处理上很重要对数据集进行反复的训练得到我们最终的预测图以及预测结果。
三、实验设置过程
利用json将我们需要的中国、美国、巴西、印度、俄罗斯、法国、英国、土耳其、阿根廷、哥伦比亚、日本等11个国家以及中国31个省自治区、直辖市在2022.0101-2022.06.19的新冠疫情数据爬取下来并将其导入我们的平台中。
1.1国内数据
结果部分
2.进行可视化处理
根据我们爬取下来的数据利用pandas、numpy、matplotlib等库将数据做一个可视化处理。
3.进行预测处理
因为这三个维度本质上都是一样的所以说我们只需要对一个维度的数据进行处理然后将其应用到其他的两个数据维度方面就可以其中我们要注意一点那就是我们得到的死亡数据中一部分出现了断层所以说我们需要经过简单的插值处理得到真实的需要处理的数据。
最后通过我们的LSTM对三个维度的数据进行训练以及预测画出疫情变化趋势图得到每一项的决定系数R2再将这三项数据取平均值得到我们最后的结果。
4.LSTM模型代码
# @Time : 2022/6/30 12:01
# @Author : 徐以鹏
# @File : 预测.py
import numpy as np
import matplotlib.pyplot as plt
import paddle
import pandas as pd
path = "/home/aistudio/work/"
Data = pd.read_csv(path + '中国.csv', index_col='dateId', parse_dates=['dateId']) # 读取文件
Data.head()
predict_name = 'confirmedCount' # 取文件中我们需要的数据
training = Data[predict_name][:'20220619'].values # 训练的数据我们取到6月19号
test = Data[predict_name]['20220620':].values # 测试的数据取到6月20号
trainlist, testlist = [0], [0] # 将训练和测试的数据都存储在我们创建好的新列表中
for i in range(1, len(training)):
trainlist.append(training[i] - training[i - 1])
for j in range(1, len(test)):
testlist.append(test[j] - test[j - 1])
# 用np.array()把我们的训练和测试的数据由列表转化为数组
training = np.array(trainlist)
test = np.array(testlist)
# 取训练集中的最小值和最大值,分别为mintrain和maxtrain
mintrain = training.min()
maxtrain = training.max()
train_set_range = maxtrain - mintrain
def my_MinMaxScaler(data):
return (data - mintrain) / (train_set_range)
def reverse_min_max_scaler(a_num):
return a_num * train_set_range + mintrain
normalized_train_set = my_MinMaxScaler(training)
normalized_test_set = my_MinMaxScaler(test)
normalized_train_set = normalized_train_set.astype('float32')
# 定义MyDataset()类,定义出需要的transform函数
class MyDataset(paddle.io.Dataset):
def __init__(self, normalized_train_set):
super(MyDataset, self).__init__()
self.train_set_data_X = []
self.train_set_data_Y = []
self.transform(normalized_train_set)
def transform(self, data):
for i in range(60, len(data)):
self.train_set_data_X.append(np.array(data[i - 60:i].reshape(-1, 1)))
self.train_set_data_Y.append(np.array(data[i]))
def __getitem__(self, index):
data = self.train_set_data_X[index]
label = self.train_set_data_Y[index]
return data, label
def __len__(self):
return len(self.train_set_data_X)
dataSet = MyDataset(normalized_train_set)
trainLoader = paddle.io.DataLoader(dataSet, batch_size=200, shuffle=False)
class StockNet(paddle.nn.Layer):
def __init__(self):
super(StockNet, self).__init__()
self.lstm = paddle.nn.LSTM(input_size=1,
hidden_size=50,
num_layers=4,
dropout=0.2,
time_major=False)
self.fc = paddle.nn.Linear(in_features=50, out_features=1)
def forward(self, inputs):
outputs, final_states = self.lstm(inputs)
y = self.fc(final_states[0][3])
return y
# 由于在训练过程中会存在的梯度消失问题所以我们采用LSTM模型来处理我们的数据以下为模型
# 此处代码缩减 防止不法利用 需要的话联系作者
# 画出预测图
def plot_predictions(test, predicted):
plt.plot(test, color='red', label='Realvalue')
plt.plot(predicted, color='black', label='Predictedvalue')
plt.title('confirmedCount_Prediction')
plt.xlabel('Days')
plt.ylabel('People')
plt.legend()
plt.show()
plot_predictions(Data[predict_name]['20220620':].values, realtest_predict)
# 计算出预测结果的r2值
from sklearn.metrics import r2_score
confirmedCount = r2_score(Data[predict_name]['20220620':].values, realtest_predict[:11])
print(r2_score(Data[predict_name]['20220620':].values, realtest_predict[:11]))
四、新冠疫情可视化
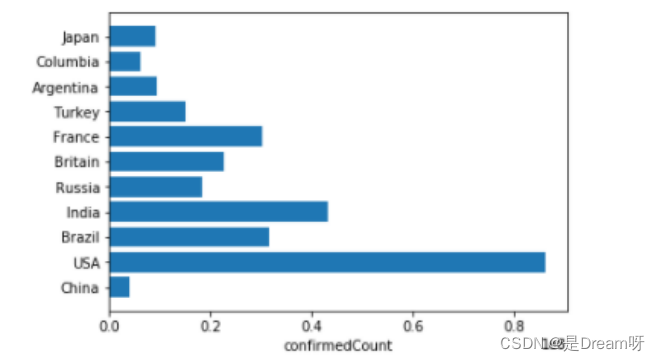
1.各国家确诊人数
plt.xlabel("confirmedCount")
plt.barh(Country,last_confirmedCount2)
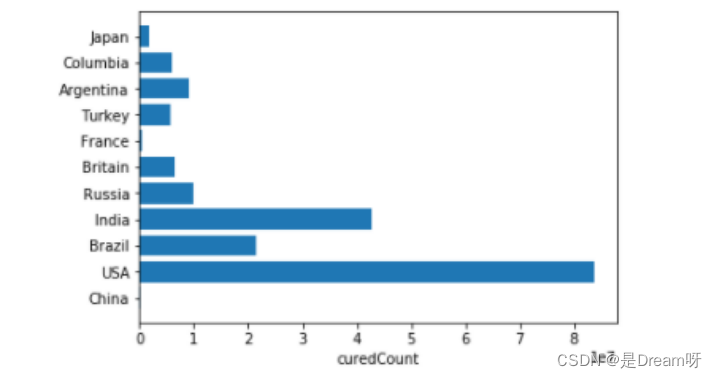
2.各国家治愈人数
plt.xlabel("curedCount")
plt.barh(Country,last_curedCount2)
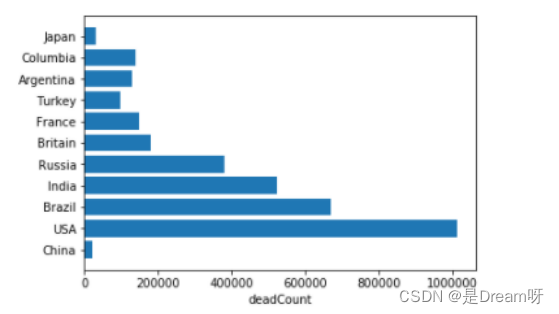
3.各国家死亡人数
plt.xlabel("deadCount")
plt.barh(Country,last_deadCount2)
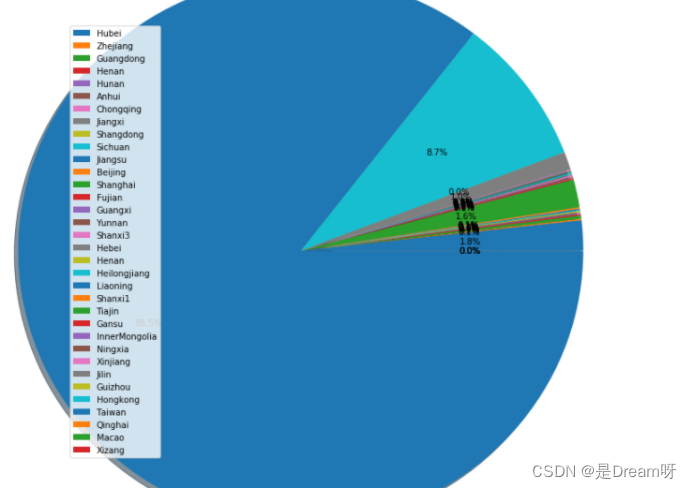
4.全国各省总确诊人数分布饼状图
plt.figure(figsize=(10,10))
plt.pie(last_confirmedCount1,radius=1.5,shadow=True,autopct='%1.1f%%')
plt.legend(Province, loc='best')
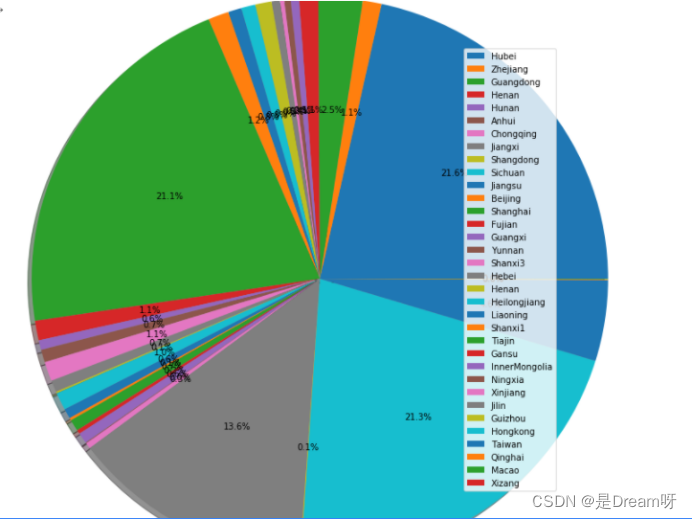
5.全国各省治愈人数
plt.figure(figsize=(10,10))
plt.pie(last_curedCount1,radius=1.5,shadow=True,autopct='%1.1f%%')
plt.legend(Province, loc='best')
五、疫情数据预测
1.2022.6.20-2022.6.30的全国确诊人数
# 画出预测图
def plot_predictions(test, predicted):
plt.plot(test, color='red', label='Realvalue')
plt.plot(predicted, color='black', label='Predictedvalue')
plt.title('confirmedCount_Prediction')
plt.xlabel('Days')
plt.ylabel('People')
plt.legend()
plt.show()
plot_predictions(Data[predict_name]['20220620':].values, realtest_predict)
# 计算出预测结果的r2值
from sklearn.metrics import r2_score
confirmedCount = r2_score(Data[predict_name]['20220620':].values, realtest_predict[:11])
print(r2_score(Data[predict_name]['20220620':].values, realtest_predict[:11]))
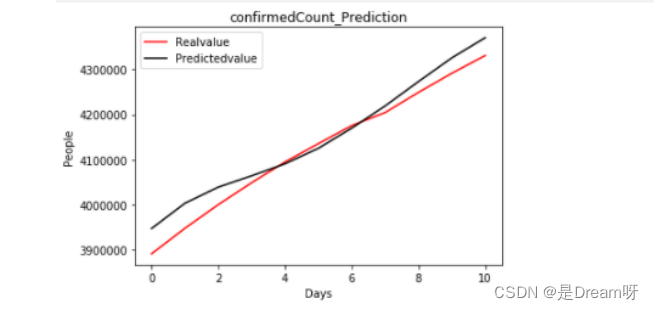
r2=0.9425994713615403
2.2022.6.20-2022.6.30的全国死亡人数
# 画出预测图
def plot_predictions(test, predicted):
plt.plot(test, color='red', label='Realvalue')
plt.plot(predicted, color='black', label='Predictedvalue')
plt.title('deadCount_Count_Prediction')
plt.xlabel('Days')
plt.ylabel('People')
plt.legend()
plt.show()
plot_predictions(Data[predict_name]['20220620':].values, realtest_predict)
# 计算出预测结果的r2值
from sklearn.metrics import r2_score
deadCount = r2_score(Data[predict_name]['20220620':].values, realtest_predict[:11])
print(r2_score(Data[predict_name]['20220620':].values, realtest_predict[:11]))
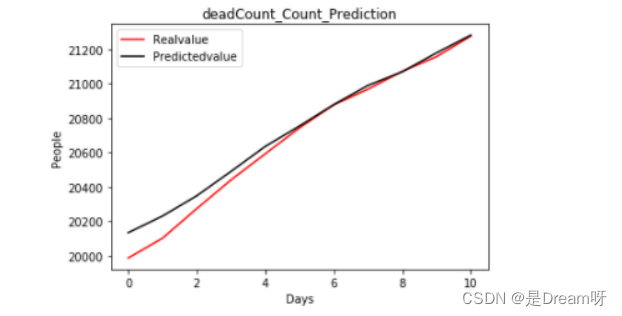
r2=0.9741672899742679
3.2022.6.20-2022.6.30的全国治愈人数
# 画出预测图
def plot_predictions(test, predicted):
plt.plot(test, color='red', label='Realvalue')
plt.plot(predicted, color='black', label='Predictedvalue')
plt.title('curedCount_Count_Prediction')
plt.xlabel('Days')
plt.ylabel('People')
plt.legend()
plt.show()
plot_predictions(Data[predict_name]['20220620':].values, realtest_predict)
# 计算出预测结果的r2值
from sklearn.metrics import r2_score
curedCount = r2_score(Data[predict_name]['20220620':].values, realtest_predict[:11])
print(r2_score(Data[predict_name]['20220620':].values, realtest_predict[:11]))
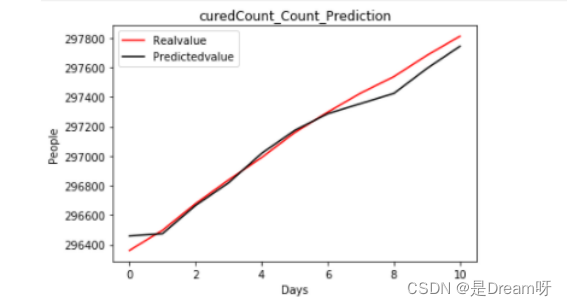
r2=0.9819537632078106
4.求出三者的平均值
# 计算出预测结果的r2值
from sklearn.metrics import r2_score
confirmedCount = r2_score(Data[predict_name]['20220620':].values, realtest_predict[:11])
print(r2_score(Data[predict_name]['20220620':].values, realtest_predict[:11]))
print((confirmedCount+curedCount+deadCount)/3)
r2=(confirmedCount+curedCount+deadCount)/3=0.96624
六、结果分析与总结
我们得到的最终的预测结果的r2值达到了0.96624说明我们的模型拟合程度非常不错可以准确的预测以后的确诊人数、死亡人数和治愈人数。
这种结果的达成离不开我们优秀的LSTM模型LSTM与RNNs一样比CNN能更好地处理时间序列的任务同时LSTM解决了RNN的长期依赖问题并且缓解了RNN在训练时反向传播带来的“梯度消失”问题。LSTM是RNN的一个优秀的变种模型继承了大部分RNN模型的特性同时解决了梯度反传过程由于逐步缩减而产生的Vanishing Gradient问题。但是LSTM本身的模型结构就相对复杂训练比起CNN来说更加耗时对于本问题而言LSTM模型预测准确可以帮助我们很好的知道疫情趋势的变化。
七、代码原工程文件分享
如果需要源码和源文件的同学自己根据需要下载文件
最后有任何问题欢迎关注下面的公众号获取第一时间消息、作者联系方式及每周抽奖等多重好礼